Research Overview
Our research focuses on the development of algorithms with provable guarantees, both in terms of running times as well as quality of the outcome. While trying to build on a solid theoretical foundation, we do not mind if our algorithms have applications in the real world. So most our results originate from a problem in an application context.
Showcase Project
OSCAR - our search engine for the complete OpenStreetMap planet data set.
Selected Publications
So far, some of our results have been published at the flagship conferences in the fields of databases (VLDB 2014), artificial intelligence (AAAI 2019, 2018, 2017, 2014, 2013, 2012, 2011), networking (INFOCOM 2007), algorithms & discrete math (SODA 2007, 2005, 2004, 2003, 2002, 2001), and computational geometry (SCG 2006, 2005, 2004, 2003, 2000, 1998).
The following is a somewhat arbitrary subset of our results, please see DBLP or Google Scholar for a more comprehensive list of our publications.
Scalable Ultrafast Almost-optimal Euclidean Shortest Paths
Funke, Koch, Proissl, Schneewind,Weiss, Weitbrecht; IJCAI 2024
Source code and data can be found here.
Sublinear Search Spaces for Shortest Path Planning in Grid and Road Networks
Blum, Funke, Storandt; Journal of Combinatorial Optimization, Springer, 2022; preliminary version at 32nd Int. Conference on Artificial Intelligence (AAAI) 2018
Shortest path planning is a fundamental building block in many applications. Hence developing efficient methods for computing shortest paths in e.g. road or grid networks is an important challenge. The most successful techniques for fast query answering rely on preprocessing. But for many of these techniques it is not fully understood why they perform so remarkably well and theoretical justification for the empirical results is missing. An attempt to explain the excellent practical performance of preprocessing based techniques on road networks (as transit nodes, hub labels, or contraction hierarchies) in a sound theoretical way are parametrized analyses, e.g., considering the highway dimension or skeleton dimension of a graph. But these parameters tend to be large (order of Θ(√n)) when the network contains grid-like substructures — which inarguably is the case for real-world road networks around the globe. In this paper, we use the very intuitive notion of bounded growth graphs to describe road networks and also grid graphs. We show that this model suffices to prove sublinear search spaces for the three above mentioned state-of-the-art shortest path planning techniques. For graphs with a large highway or skeleton dimension, our results turn out to be superior. Furthermore, our preprocessing methods are close to the ones used in practice and only require randomized polynomial time.
Rational Points on the Unit Sphere: Approximation Complexity and Practical Constructions
Bahrdt, Seybold; accepted at 42nd Int. Symp. on Symbolic and Algebraic Computation (ISSAC) 2017
Each non-zero point in R d identifies a closest point x on the unit sphere. We are interested in computing an ε-approximation y for x, that is exactly on the unit sphere and has low bit size. We revise lower bounds on rational approximations and provide explicit, spherical instances. We prove that floating-point numbers can only provide trivial solutions to the sphere equation in R 2 and R 3 . Moreover, we show how to construct a rational point with denominators of at most 32(d − 1) 2 /ε 2 for any given ε, improving on a previous result. The method further benefits from algorithms for simultaneous Diophantine approximation. Our open-source implementation and experiments demonstrate the practicality of our approach in the context of massive data sets Geo-referenced by latitude and longitude values.
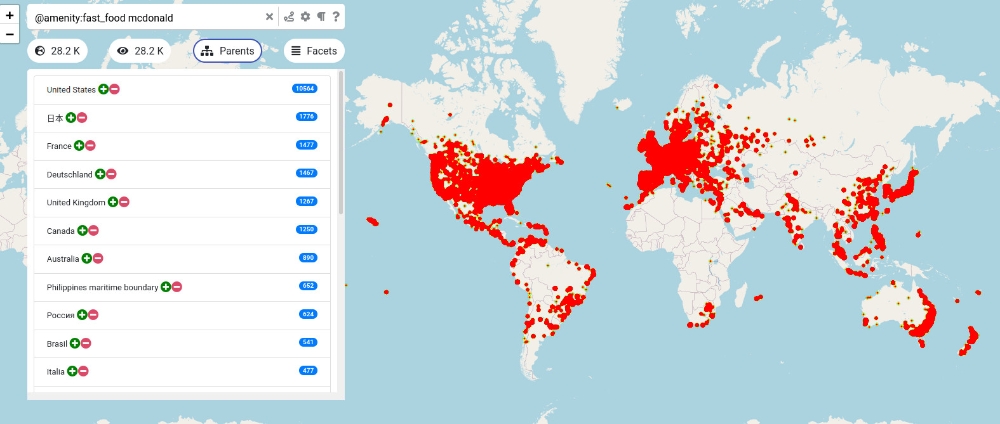
On k-path Covers and their Applications
Funke, Nusser, Storandt; VLDB Journal 2016; preliminary version at 40th Int. Conf. on Very Large Databases (VLDB) 2014; Best Paper Award
For a directed graph G with vertex set V we call a subset C ⊆ V a k-(All-)Path Cover if C contains a node from any path consisting of k nodes. This paper considers the problem of constructing small k-Path Covers in the context of road networks with millions of nodes and edges. In many application scenarios the set C and its induced overlay graph constitute a very compact synopsis of G which is the basis for the currently fastest data structure for personalized shortest path queries, visually pleasing overlays of subsampled paths, and efficient reporting, retrieval and aggregation of associated data in spatial network databases. Apart from a theoretical investigation of the problem, we provide efficient algorithms that produce very small k-Path Covers for large real-world road networks (with a posteriori guarantees via instance-based lower bounds).

Placement of Loading Stations for Electric Vehicles
Funke, Nusser, Storandt; Journal of Artificial Intelligence Research 2015; preliminary version at 28th Int. Conference on Artificial Intelligence (AAAI) 2014; Honorable Mention in the Outstanding Paper Award Category
Compared to conventional cars, electric vehicles still suffer from a considerably shorter cruising range. Combined with the sparsity of battery loading stations, the complete transition to E-mobility still seems a long way to go. In this paper, we consider the problem of placing as few loading stations as possible such that on any shortest path there are enough to guarantee sufficient energy supply. This means, that EV owners no longer have to plan their trips ahead incorporating loading station locations, and are no longer forced to accept long detours to reach their destinations. We show how to model this problem and introduce algorithms which construct close-to-optimal solutions even in large road networks.
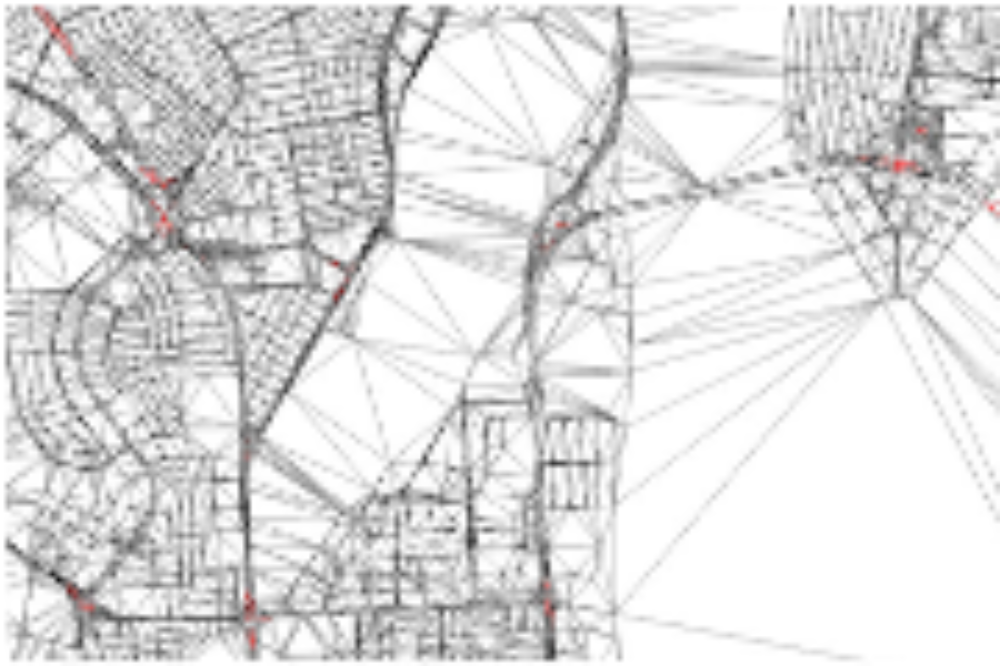
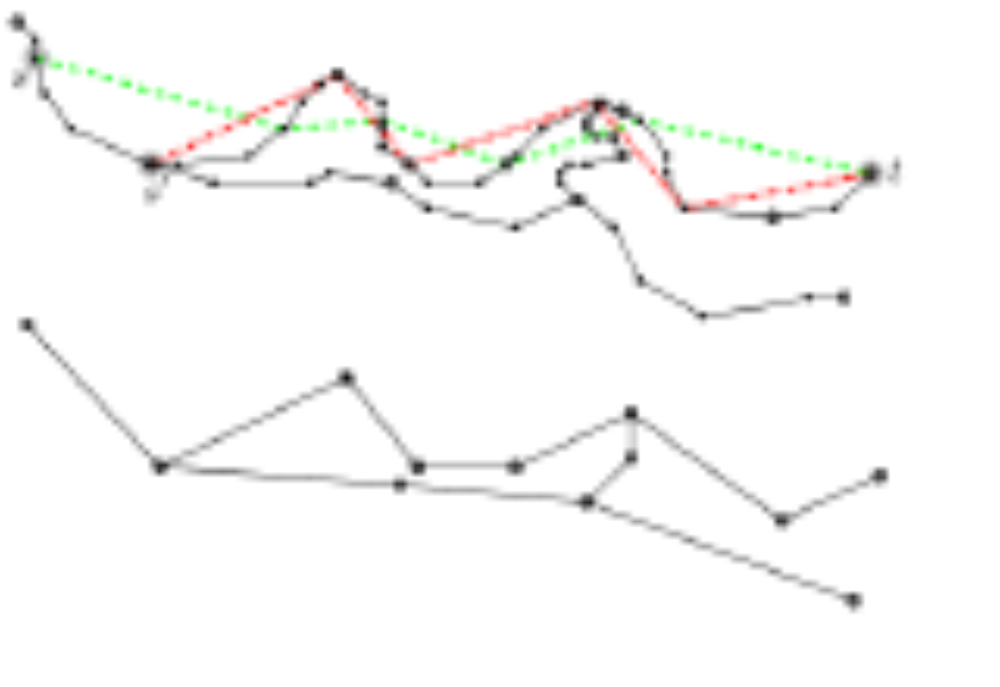
Path Shapes - An Alternative Method for Map Matching and Fully Autonomous Self Localization
Funke, Storandt; 19th ACM SIGSPATIAL Int. Conf. on Advances in Geographic Information Systems (GIS) 2011; Best Paper Award
We propose a novel scheme for map matching and fully autonomous self-localization. Our scheme is based on the unique characteristics of the shape of paths in a road network. As uniqueness of path shapes comes as no surprise in a world of infinite precision, we develop robust means of comparing shapes of paths under imprecisions. Even under this fuzzy comparison model, path shapes turn out to be sufficiently characteristic to allow for map matching or fully autonomous self-localization. We design an efficient data structure which allows for very fast path shape queries.
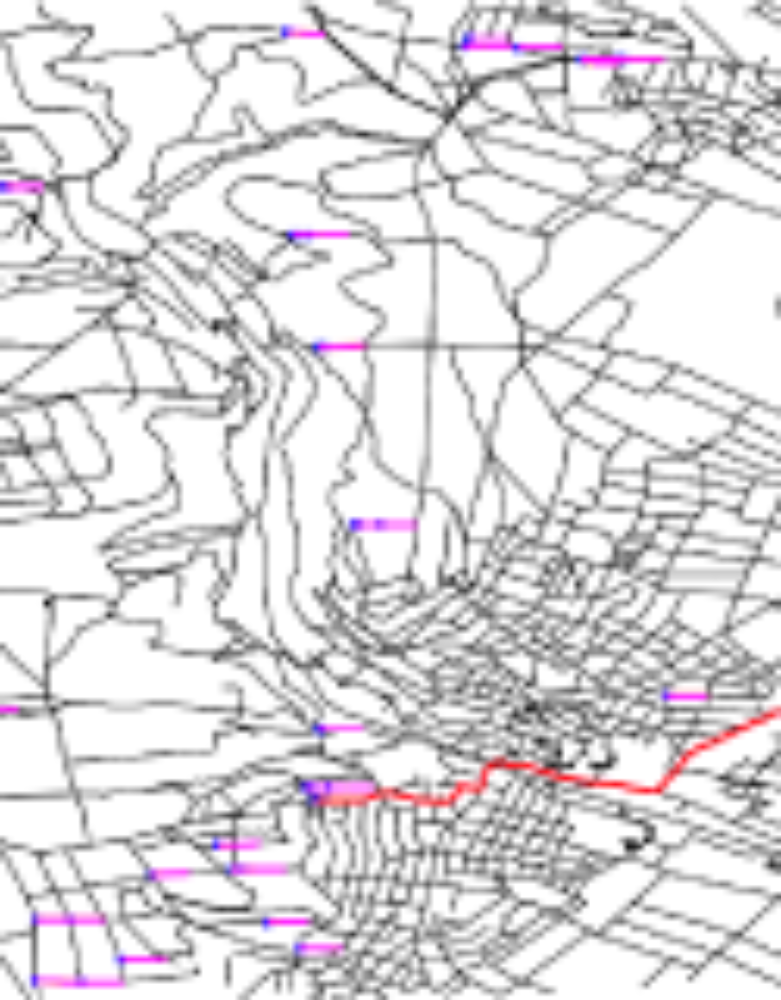
Fast Routing in Road Networks with Transit Nodes
Bast, Funke, Sanders, Schultes; Brevia in Science Apr 27th 2007
When you drive to somewhere `far away’, you will leave your current location via one of only a few `important’ traffic junctions. Starting from this informal observation, we develop an algorithmic approach —transit node routing — that allows us to reduce quickest-path queries in road networks to a small number of table lookups. We present two implementations of this idea, one based on a simple grid data structure and one based on highway hierarchies. For the road map of the United States, our best query times improve over the best previously published figures by two orders of magnitude. Our results exhibit various trade-offs between average query time, preprocessing time, and storage overhead.
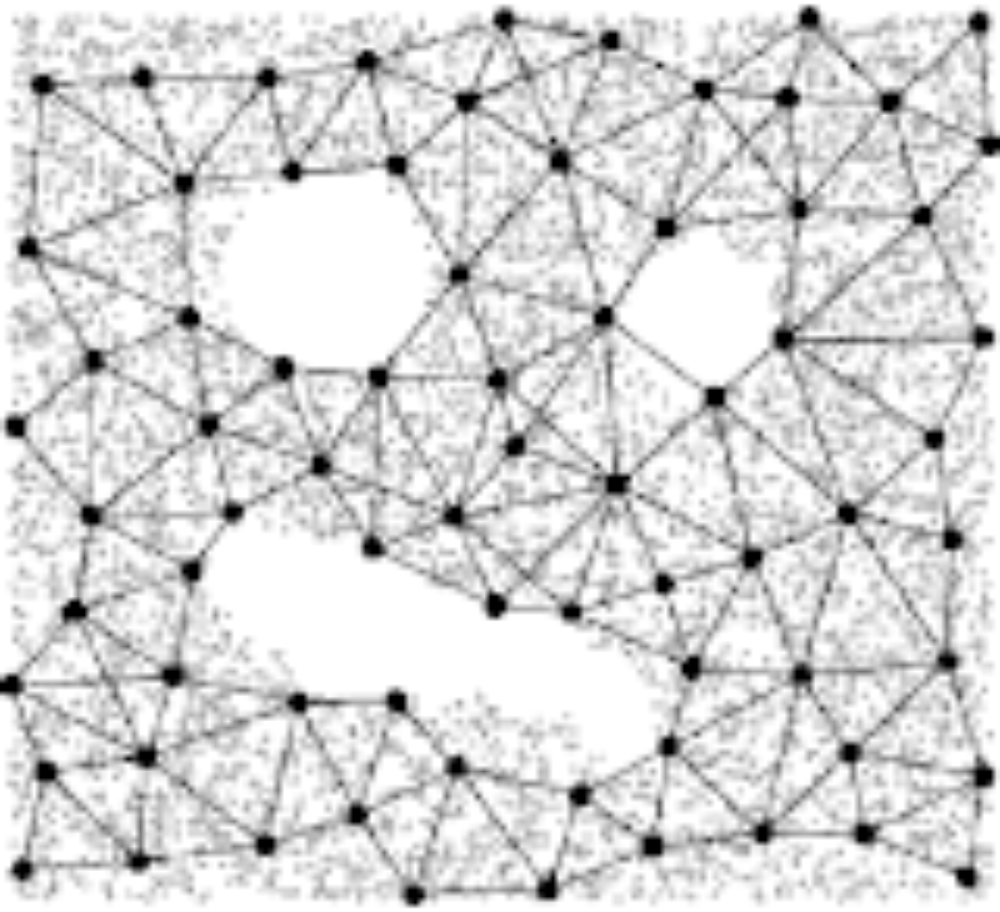
Guaranteed-delivery Geographic Routing under uncertain Node Locations
Funke, Milosavljevic; 26th Ann. IEEE Conference on Computer Communications (INFOCOM) 2007
Geographic routing protocols like GOAFR or GPSR rely on exact location information at the nodes, as when the greedy routing phase gets stuck at a local minimum, they require, as a fallback, a planar subgraph whose identification, in all existing methods, depends on exact node positions. In practice, however, location information at the network nodes is hardly precise; be it because the employed location hardware, such as GPS, exhibits an inherent measurement imprecision, or because the localization protocols which estimate positions of the network nodes cannot do so without errors. In this paper we propose a novel naming and routing scheme that can handle the uncertainty in location information. It is based on a macroscopic variant of geographic greedy routing, as well as a macroscopic planarization of the communication graph. If an upper bound on the deviation from true node locations is available, our routing protocol guarantees delivery of messages. Due to its macroscopic view, our routing scheme also produces shorter and more load-balanced paths than common geographic routing schemes, in particular in sparsely connected networks or in the presence of obstacles.
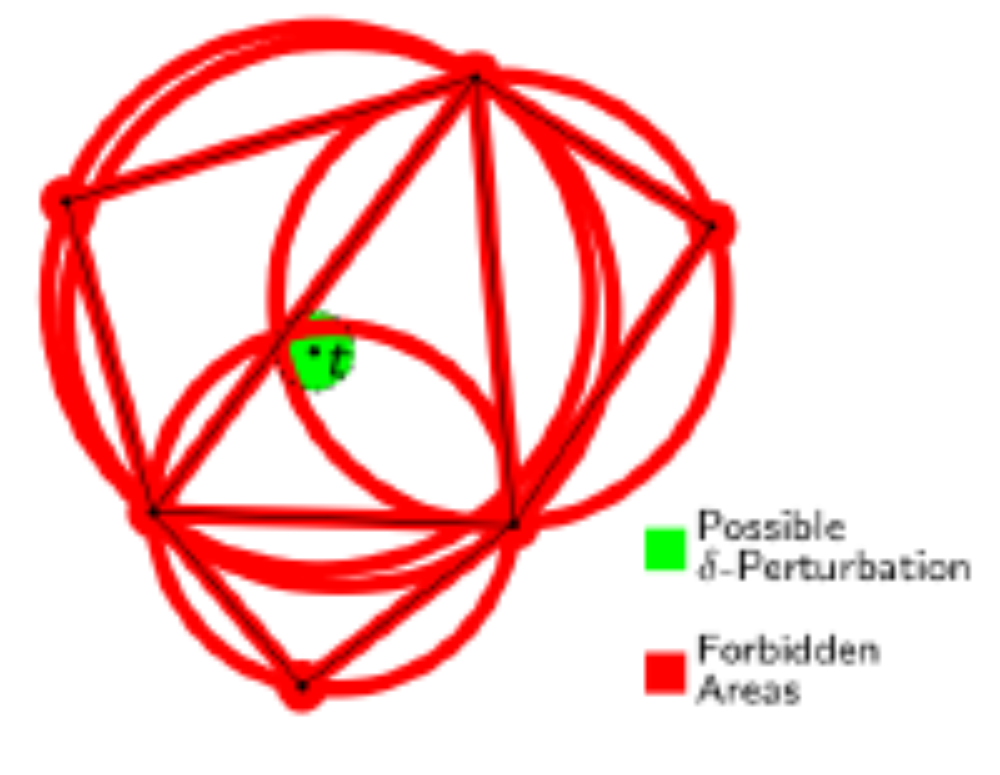
Controlled Perturbation for Delaunay Triangulations
Funke, Klein, Mehlhorn, Schmitt; 16th ACM-SIAM Symp. on Discrete Algorithms (SODA) 2005
Most geometric algorithms are idealistic in the sense that they are designed for the Real-RAM model of computation and for inputs in general position. Real inputs may be degenerate and floating point arithmetic is only an approximation of real arithmetic. Perturbation replaces an input by a nearby input which is (hopefully) in general position and on which the algorithm can be run with floating point arithmetic. Controlled perturbation as proposed by Halperin et al. calls for more: control over the amount of perturbation needed for a given precision of the floating point system. Or conversely, a control over the precision needed for a given amount of perturbation. Halperin et al. gave controlled perturbation schemes for arrangements of polyhedral surfaces, spheres, and circles.
We extend their work and point out that controlled perturbation is a general scheme for converting idealistic algorithms into algorithms which can be executed with floating point arithmetic. We also show how to use controlled perturbation in the context of randomized geometric algorithms without deteriorating the running time. Finally, we give concrete schemes for planar Delaunay triangulations and convex hulls and Delaunay triangulations in arbitrary dimensions. We analyze the relation between the perturbation amount and the precision of the floating point system. We also report about experiments with a planar Delaunay diagram algorithm.
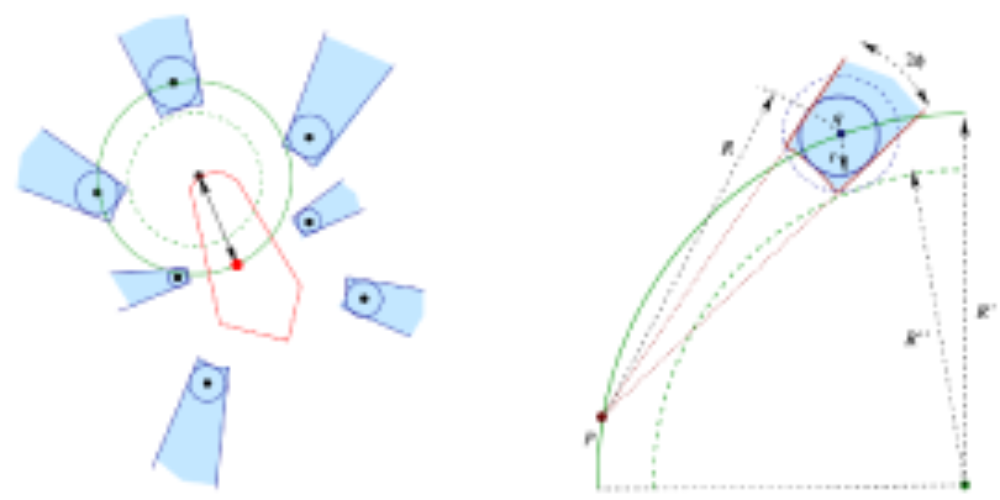
Smooth-Surface Reconstruction in Near-Linear Time
Funke, Ramos; 13th ACM-SIAM Symp. on Discrete Algorithms (SODA) 2002
A surface reconstruction algorithm takes as input a set of sample points from an unknown closed and smooth surface in 3-d space, and produces a piece-wise linear approximation of the surface that contains the sample points. This problem has received considerable attention in computer graphics and more recently in computational geometry. In the latter area, four different algorithms (by Amenta and Bern `98; Amenta, Choi, Dey and Leekha `00; Amenta, Choi and Kolluri `00; Boissonnat and Cazals `00) have been proposed. These algorithms have a correctness guarantee: if the sample is sufficiently dense then the output is a good approximation to the original surface. They have unfortunately a worst-case running time that is quadratic in the size of the input. This is so because they are based on the construction of 3-d Voronoi diagrams or Delaunay tetrahedrizations, which can have quadratic size. Even worse, according to recent work (Erickson `01), there are surfaces for which this is the case even when the sample set is `locally uniform’ on the surface. In this paper, we describe a new algorithm that also has a correctness guarantee but whose worst-case running time is almost linear. In fact, $O(n\log n)$ where $n$ is the input size. As in some of the previous algorithms, the piece-wise linear approximation produced by the new algorithm is a subset of the 3-d Delaunay tetrahedrization; however, this is obtained by computing only the relevant parts of the 3-d Delaunay structure. The algorithm first estimates for each sample point the surface normal and a parameter that is then used to `decimate’ the set of samples. The resulting subset of sample points is locally uniform and so a reconstruction based on it can be computed using a simple and fast algorithm. In a last step, the decimated points are incorporated into the reconstruction.